Cómo funciona la biometría de voz: guía completa 2025
Guía completa sobre cómo funciona la biometría de voz: desde la ciencia detrás de tu voz única hasta implementación práctica. Todo lo que necesitás saber.
Phonomica
Equipo de contenido
15 de marzo de 2023
Actualizado: 15 de enero de 2025
Cómo funciona la biometría de voz: guía completa 2025
Tiempo de lectura: 15 minutos
Última actualización: Enero 2025
Tu voz es tan única como tu huella digital. La biometría de voz aprovecha esta unicidad para verificar tu identidad en segundos, sin contraseñas, sin preguntas de seguridad, sin fricción.
En esta guía vamos a explicar cómo funciona esta tecnología, desde la ciencia fundamental hasta la implementación práctica. Ya seas un decisor de tecnología evaluando soluciones, un desarrollador planeando una integración, o simplemente alguien curioso sobre cómo funciona, esta guía tiene lo que necesitás.
Tabla de contenidos
- ¿Qué es la biometría de voz?
- La ciencia detrás de la voz única
- El proceso paso a paso
- Modelos y tecnología
- Métricas de precisión
- Anti-spoofing: Protección contra deepfakes
- Casos de uso
- Cómo elegir un proveedor
- Preguntas frecuentes
¿Qué es la biometría de voz?
La biometría de voz (o voice biometrics en inglés) es una tecnología que permite identificar o verificar a una persona analizando las características únicas de su voz.
A diferencia de una contraseña que podés compartir, o una tarjeta que podés perder, tu voz viaja con vos. Y a diferencia de otros biométricos como huellas dactilares o iris, no requiere hardware especializado: un micrófono (como el de tu teléfono) es suficiente.
Verificación vs Identificación
Es importante distinguir dos operaciones diferentes:
| Operación | Pregunta que responde | Uso típico |
|---|---|---|
| Verificación (1:1) | “¿Es esta persona quien dice ser?” | Autenticación de usuarios |
| Identificación (1:N) | “¿Quién es esta persona?” | Búsqueda en bases de datos, blacklists |
La verificación compara una voz contra un voiceprint específico. Es lo que usarías para autenticar a un cliente en un call center: “Decimos que es Juan García, ¿su voz coincide con el voiceprint de Juan García?”
La identificación busca una voz en toda una base de datos. Es lo que usarías para detectar si alguien está en una lista negra: “Esta voz que estoy escuchando, ¿está en mi lista de 10,000 defraudadores conocidos?”
La ciencia detrás de la voz única
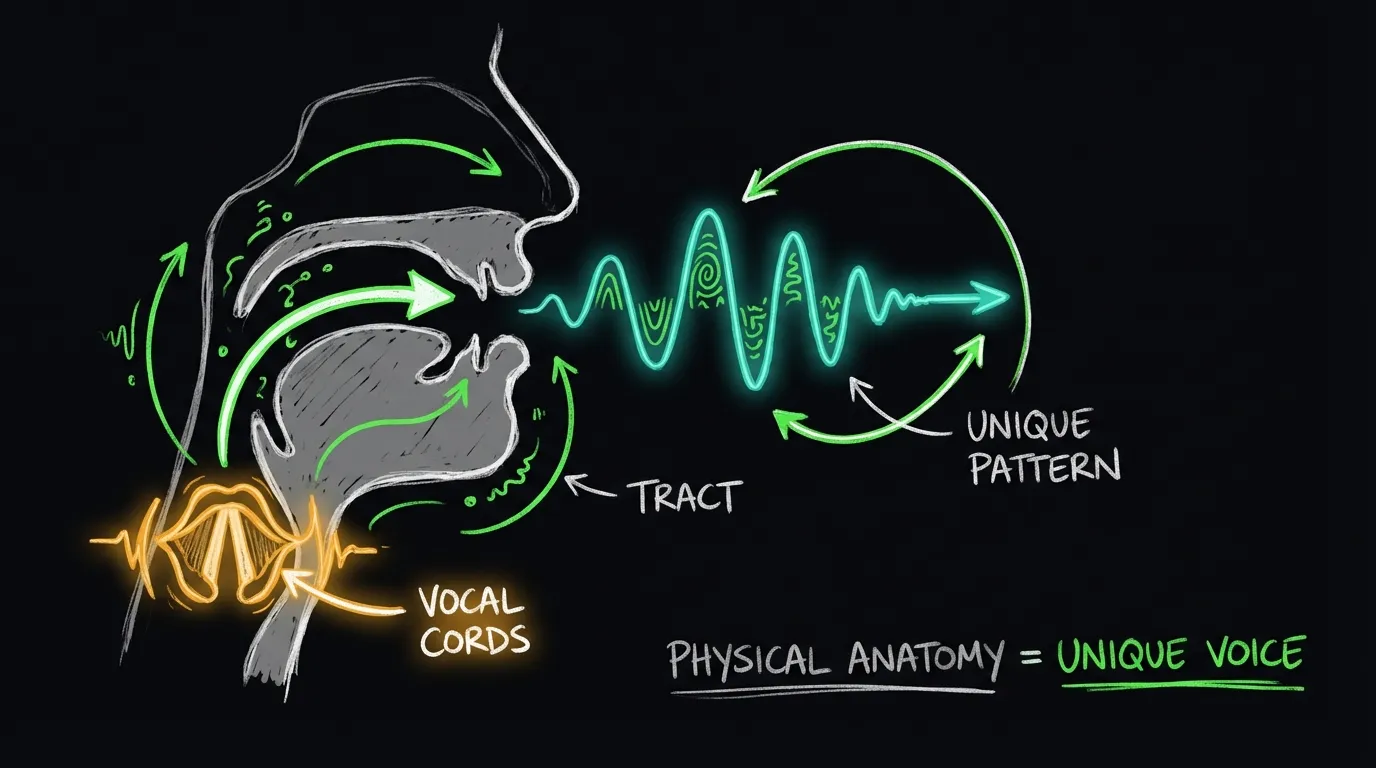
¿Por qué tu voz es única? La respuesta está en la anatomía y el comportamiento.
Componentes fisiológicos
Tu voz está determinada por factores físicos que son difíciles de imitar:
Cuerdas vocales: El largo, grosor y tensión de tus cuerdas vocales determinan la frecuencia fundamental de tu voz. Esto es parcialmente por qué hombres y mujeres suenan diferente.
Tracto vocal: La forma de tu garganta, boca y cavidades nasales actúa como un filtro único. Cada persona tiene una combinación diferente de resonancias.
Pulmones y diafragma: La capacidad pulmonar y la forma de respirar afectan el flujo de aire y por lo tanto las características del sonido.
Componentes comportamentales
Además de la anatomía, hay patrones aprendidos:
- Velocidad de habla: Qué tan rápido hablás
- Entonación: Cómo subís y bajás el tono
- Pausas: Dónde y cómo hacés pausas
- Pronunciación: Acentos regionales y personales
- Vocabulario: Palabras y frases que usás frecuentemente
El “voiceprint”
Cuando combinás todos estos factores, obtenés lo que llamamos un voiceprint (huella vocal): una representación matemática de las características únicas de una voz.
Técnicamente, un voiceprint moderno es un vector de 192-512 números (llamado “embedding”) que captura las características discriminativas de una voz.
Este embedding tiene propiedades interesantes:
- Voces de la misma persona generan embeddings cercanos
- Voces de personas diferentes generan embeddings lejanos
- La “distancia” entre embeddings indica similitud
El proceso paso a paso
La biometría de voz involucra dos fases principales: enrollment (registro) y verificación.
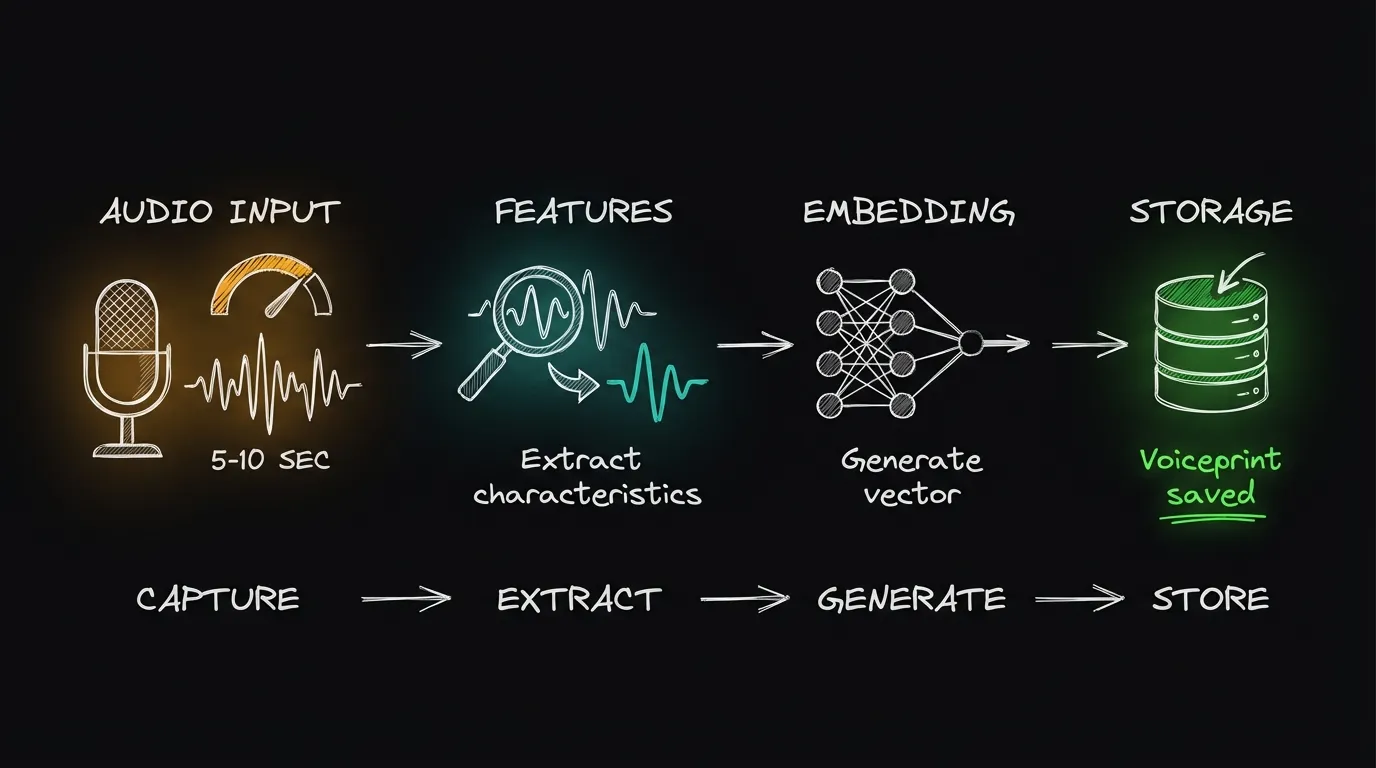
Fase 1: Enrollment
El enrollment es el proceso de registrar el voiceprint de un usuario por primera vez.
1. Usuario habla → 2. Audio procesado → 3. Features extraídas → 4. Embedding generado → 5. Voiceprint almacenadoPaso 1: Captura de audio El usuario habla durante 5-10 segundos (en sistemas modernos, 3 segundos pueden ser suficientes). Puede ser texto libre (“text-independent”) o una frase específica (“text-dependent”).
Paso 2: Preprocesamiento El audio pasa por varios filtros:
- Reducción de ruido
- Normalización de volumen
- Voice Activity Detection (VAD) para extraer solo segmentos con voz
- Eliminación de silencios
Paso 3: Extracción de features Se extraen características del audio que son informativas sobre el hablante:
- Mel-frequency cepstral coefficients (MFCC)
- Características espectrales
- Información prosódica
Paso 4: Generación de embedding Un modelo de deep learning (como ECAPA-TDNN o TitaNet) procesa las features y genera un vector numérico de 192-512 dimensiones que representa la voz.
Paso 5: Almacenamiento El embedding se normaliza (generalmente a norma L2 = 1) y se almacena en una base de datos. Nota importante: se almacena el embedding, no el audio original.
Fase 2: Verificación
Cuando el usuario quiere autenticarse, el proceso es similar:
1. Usuario habla → 2. Audio procesado → 3. Embedding generado → 4. Comparado con voiceprint → 5. DecisiónPasos 1-4: Idénticos al enrollment, pero el audio suele ser más corto (1-3 segundos).
Paso 5: Comparación Se calcula la similitud coseno entre el embedding nuevo y el voiceprint almacenado:
similitud = (embedding_nuevo · voiceprint) / (|embedding_nuevo| × |voiceprint|)El resultado es un número entre 0 y 1:
- 0: Completamente diferentes
- 1: Idénticos
Paso 6: Decisión Se compara la similitud contra un threshold (umbral):
- Si similitud ≥ threshold → MATCH (es la misma persona)
- Si similitud < threshold → NO MATCH (no es la misma persona)
Ejemplo numérico
Voiceprint almacenado de Juan: [0.12, -0.34, 0.56, ..., 0.23] (192 números)
Embedding de la llamada actual: [0.11, -0.35, 0.55, ..., 0.24] (192 números)
Similitud coseno: 0.94
Threshold: 0.85
Decisión: 0.94 > 0.85 → MATCH ✓Modelos y tecnología
Los sistemas modernos de biometría de voz usan redes neuronales profundas. Estos son los modelos más relevantes:
ECAPA-TDNN
Emphasized Channel Attention, Propagation and Aggregation - Time Delay Neural Network
ECAPA-TDNN es el modelo más usado en la industria. Desarrollado por investigadores de SpeechBrain, combina varias innovaciones:
- Atención a nivel de canal: Se enfoca en las características más discriminativas
- Res2Net: Captura información a múltiples escalas
- SE blocks: Squeeze-and-Excitation para mejor pooling
Precisión: EER de 0.87% en VoxCeleb
Tamaño: ~22 millones de parámetros
Latencia típica: 100-200ms
TitaNet
Desarrollado por NVIDIA, TitaNet es una familia de modelos optimizados para diferentes casos de uso:
- TitaNet-L: Máxima precisión (EER 0.68%)
- TitaNet-M: Balance precisión/tamaño
- TitaNet-S: Optimizado para edge/móvil (6M params)
Ventaja: Disponible en NVIDIA NeMo con implementación optimizada para inference.
Comparativa
| Modelo | EER (VoxCeleb) | Parámetros | Mejor para |
|---|---|---|---|
| ECAPA-TDNN | 0.87% | 22M | Uso general, buen balance |
| TitaNet-L | 0.68% | 25M | Máxima precisión |
| TitaNet-S | 1.2% | 6M | Edge/móvil |
| x-vector | 2.1% | 4M | Legacy, recursos limitados |
Text-independent vs Text-dependent
| Característica | Text-independent | Text-dependent |
|---|---|---|
| Frase requerida | Cualquiera | Específica (“Mi voz es mi contraseña”) |
| UX | Mejor (habla natural) | Peor (debe recordar frase) |
| Seguridad | Buena | Potencialmente mejor contra replay |
| Adopción | ~90% de nuevas impl. | ~10%, decreciendo |
La tendencia clara es hacia text-independent por mejor UX y flexibilidad.
Métricas de precisión
Para evaluar un sistema de biometría de voz, necesitás entender estas métricas:
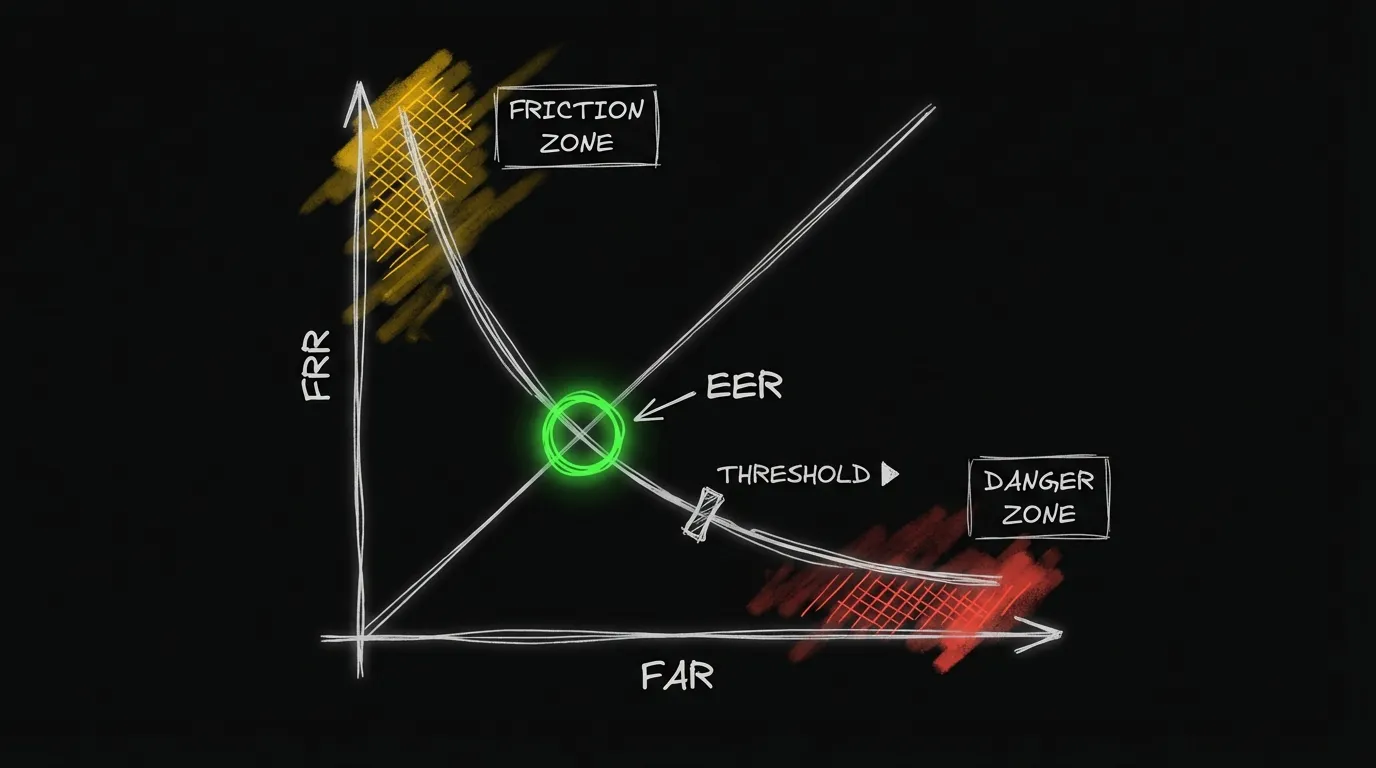
EER (Equal Error Rate)
El EER es el punto donde la tasa de aceptar impostores (FAR) es igual a la tasa de rechazar legítimos (FRR).
- FAR (False Acceptance Rate): Porcentaje de impostores aceptados incorrectamente
- FRR (False Rejection Rate): Porcentaje de usuarios legítimos rechazados incorrectamente
Un EER más bajo es mejor. Los sistemas modernos logran:
- Laboratorio: <1% EER
- Producción (condiciones ideales): 1-2% EER
- Producción (condiciones reales): 2-4% EER
Threshold y trade-offs
El threshold permite ajustar el balance entre seguridad y usabilidad:
| Threshold | FAR | FRR | Caso de uso |
|---|---|---|---|
| Bajo (0.70) | Alto (~5%) | Bajo (~1%) | Alta usabilidad, baja seguridad |
| Medio (0.80) | Medio (~1%) | Medio (~3%) | Balance |
| Alto (0.85) | Bajo (~0.5%) | Alto (~5%) | Alta seguridad, más fricción |
En Phonomica, esto se configura con niveles de sensibilidad:
- LOW: Mayor usabilidad
- MEDIUM: Balance (default)
- HIGH: Mayor seguridad
Factores que afectan la precisión
- Calidad de audio: Ruido, codec, ancho de banda
- Duración del audio: Más audio = más precisión
- Estado del usuario: Enfermo, emocionado, cansado
- Canal: Diferencias entre enrollment y verificación
- Tiempo: Voces cambian gradualmente
Anti-spoofing: Protección contra deepfakes
La biometría de voz por sí sola es vulnerable a ataques. El anti-spoofing (o liveness detection) detecta intentos de engañar al sistema.
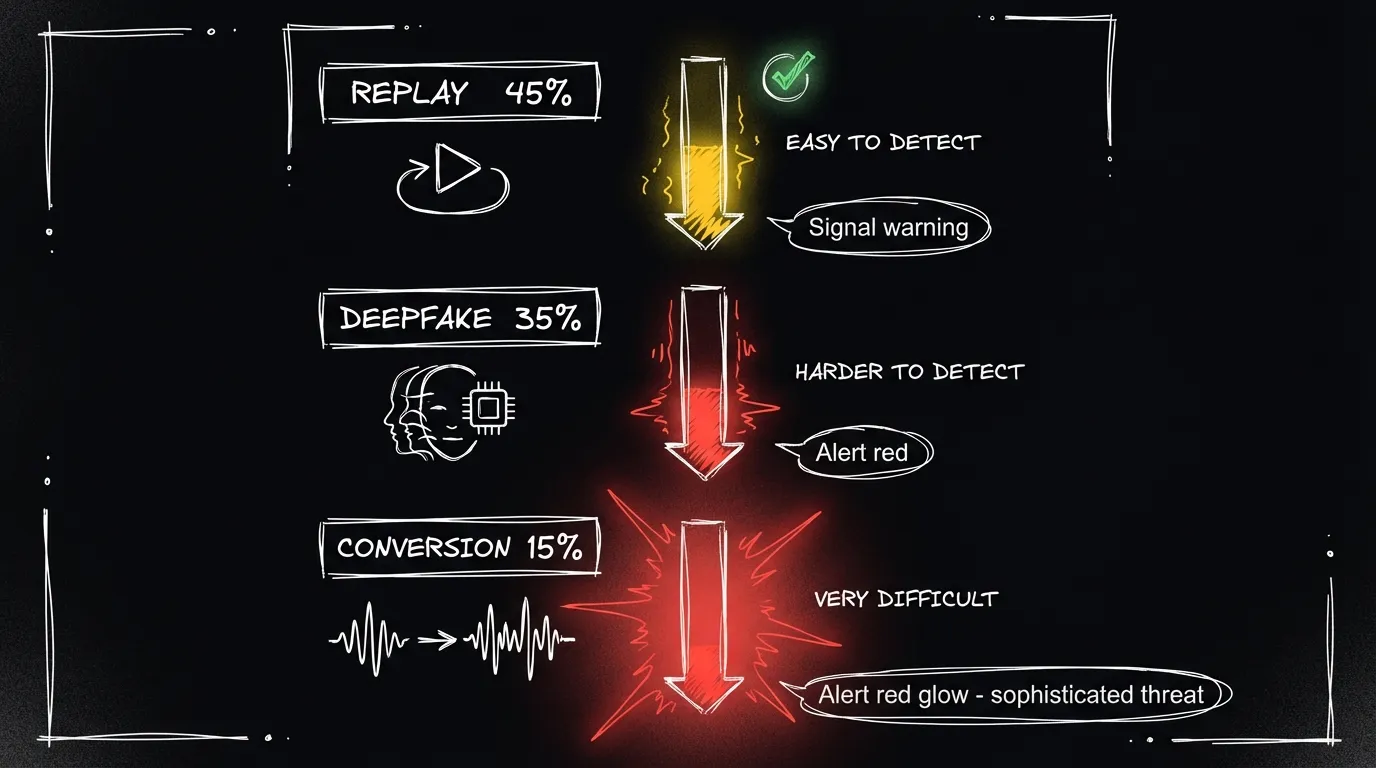
Tipos de ataques
| Ataque | Descripción | Prevalencia |
|---|---|---|
| Replay | Reproducir una grabación del usuario | 45% |
| Deepfake/Síntesis | Generar voz con IA | 35% |
| Voice conversion | Modificar voz propia para sonar como otro | 15% |
| Otros | Concatenación, etc. | 5% |
Cómo funciona la detección
Los sistemas anti-spoof analizan el audio buscando artefactos de manipulación:
Para replay:
- Artefactos de grabación (ambiente, reverberación)
- Características del canal inconsistentes
- Falta de variabilidad natural
Para deepfake/síntesis:
- Artefactos de vocoder
- Patrones espectrales antiNaturales
- Falta de variabilidad en respiración, pausas
Para voice conversion:
- Inconsistencias en formantes
- Transiciones antiNaturales
- Artefactos de procesamiento
Modelos de anti-spoofing
| Modelo | Técnica | EER (ASVspoof) |
|---|---|---|
| AASIST | Attention + spectro-temporal | <1% |
| RawNet2 | Raw audio end-to-end | ~1.5% |
| LCNN | Light CNN | ~2% |
El desafío de los deepfakes modernos
Las herramientas como ElevenLabs y OpenVoice generan audio de alta calidad que es difícil de detectar con modelos estáticos. La solución es anti-spoof adaptativo:
- Detectar nuevas herramientas de síntesis
- Recolectar ejemplos
- Actualizar modelos continuamente
- Deploy en horas, no meses
En Phonomica, actualizamos nuestros modelos de anti-spoof semanalmente para detectar las últimas herramientas.
Casos de uso
Contact Centers
El caso de uso más maduro. La biometría de voz reemplaza las preguntas de seguridad (“¿cuál es el nombre de su mascota?”) con verificación automática.
Beneficios medidos:
- Reducción de AHT: 30-45 segundos
- Reducción de fraude: 70-90%
- Mejora de NPS: +40-60 puntos en autenticación
Ejemplo de flujo:
- Cliente llama
- IVR captura audio natural durante los primeros segundos
- Sistema verifica contra voiceprint
- Agente recibe resultado: “Cliente verificado” o “Verificación pendiente”
Banca
Autenticación para banca telefónica y transacciones de alto riesgo.
Casos específicos:
- Consulta de saldo y movimientos
- Transferencias sobre cierto monto
- Cambios de datos sensibles
- Recuperación de cuenta
Fintech
Autenticación como segundo factor en apps móviles.
Modelo típico:
- Enrollment durante KYC (onboarding)
- Verificación para transacciones de riesgo
- Opcional: verificación periódica de “alive and still you”
Gobierno
Verificación de ciudadanos para servicios remotos.
Ejemplos:
- Verificación de beneficiarios de programas sociales
- Autenticación en trámites telefónicos
- Líneas de emergencia y denuncia
Cómo elegir un proveedor
Si estás evaluando proveedores de biometría de voz, usá este checklist:
Checklist técnico
- EER demostrable: <2% en condiciones similares a las tuyas
- Latencia aceptable: <500ms para UX fluida
- Anti-spoofing incluido: Especialmente deepfake detection
- Actualización de modelos: ¿Con qué frecuencia actualizan anti-spoof?
- Text-independent: Capacidad de verificar con habla natural
- API bien documentada: Integración rápida y clara
- SDKs para tus plataformas: Mobile, web, server-side
Checklist de negocio
- Pricing transparente: Sabés exactamente cuánto vas a pagar
- Trial/POC: Podés probar antes de comprometerte
- SLA claro: Uptime, latencia, soporte
- Compliance: GDPR, regulaciones locales
- Experiencia en tu industria: Referencias comprobables
Checklist de compliance
- Procesamiento de datos: ¿Dónde se procesan y almacenan?
- Consentimiento: ¿Herramientas para gestión de consentimiento?
- Derecho al olvido: ¿Proceso para eliminar voiceprints?
- Auditoría: ¿Logs suficientes para auditoría?
Red flags 🚩
- No ofrecen POC/trial
- No tienen anti-spoofing o es “opcional”
- No pueden demostrar métricas en condiciones reales
- Pricing opaco o por “consultar”
- No tienen experiencia en tu geografía/industria
Preguntas frecuentes
¿Qué pasa si me resfrío?
Un resfrío típico no afecta significativamente la verificación. Los sistemas modernos son robustos a cambios temporales en la voz.
Si la congestión es severa, el sistema puede rechazar la verificación. En ese caso, el usuario puede autenticarse por un método alternativo y re-enrollar cuando se recupere.
¿Pueden robar mi voz?
El voiceprint (embedding) no se puede “revertir” a audio. Es como un hash: podés verificar si algo coincide, pero no podés reconstruir el original.
Sin embargo, sí existen riesgos:
- Grabaciones de tu voz pueden usarse para crear deepfakes
- Por eso el anti-spoofing es crítico
¿Funciona con cualquier idioma?
Sí. Los modelos modernos son agnósticos al idioma. El sistema captura características de la voz, no del contenido.
Dicho esto, el idioma de enrollment y verificación debería ser similar para mejores resultados.
¿Cuánto audio se necesita?
- Enrollment: 5-10 segundos (algunos sistemas: 3 segundos)
- Verificación: 1-3 segundos de voz activa
Más audio = más precisión, pero con retornos decrecientes después de cierto punto.
¿Qué pasa si alguien me graba?
Si alguien reproduce una grabación tuya, un sistema con anti-spoofing lo detectará. Los replay attacks son el tipo de ataque más común y los sistemas modernos los detectan con >95% de efectividad.
¿Qué tan seguro es comparado con otros métodos?
| Método | Vulnerabilidades | Conveniencia |
|---|---|---|
| Contraseña | Phishing, robo, olvido | Baja |
| SMS OTP | SIM swapping, intercepción | Media |
| Huella digital | Requiere hardware, falsificación | Media |
| Reconocimiento facial | Fotos, luz, deepfakes visuales | Alta |
| Biometría de voz + anti-spoof | Deepfakes sofisticados | Alta |
La biometría de voz con anti-spoofing ofrece un buen balance de seguridad y conveniencia.
¿Funciona en un call center ruidoso?
Depende de cuán ruidoso. Los sistemas modernos incluyen reducción de ruido, pero hay límites. Recomendaciones:
- SNR (signal-to-noise ratio) mínimo: 15dB
- Usar headsets con cancelación de ruido
- Enrollment en condiciones similares a verificación
¿Qué tan rápido es?
- Verificación: <1 segundo (típicamente 200-400ms)
- Enrollment: <2 segundos de procesamiento
- Identificación 1:N: Depende del tamaño de la base, pero <1 segundo para miles de voiceprints
Conclusión
La biometría de voz evolucionó de tecnología experimental a infraestructura crítica. Con los deepfakes en aumento, la autenticación tradicional (contraseñas, preguntas de seguridad) ya no es suficiente.
Los sistemas modernos ofrecen:
- Precisión: EER <2% en producción
- Velocidad: <1 segundo de latencia
- Seguridad: Anti-spoofing contra deepfakes
- Conveniencia: Sin hardware adicional, sin fricción para el usuario
Si todavía estás usando preguntas de seguridad o PINs para autenticar usuarios, es hora de evaluar biometría de voz.
Próximos pasos
¿Querés ver la biometría de voz en acción?
¿Querés conocer la tecnología?
¿Querés conocer el pricing?
Recursos relacionados
- EER, FAR, FRR: Entendiendo las métricas de biometría
- La amenaza de los deepfakes de voz: Guía 2024
- ROI de biometría de voz en contact centers
¿Tenés preguntas que no respondimos? Contactanos y las agregamos a esta guía.
Artículos relacionados
ECAPA-TDNN vs TitaNet: comparación de modelos de biometría de voz
Comparación técnica entre ECAPA-TDNN y TitaNet, los dos modelos más usados en biometría de voz. Cuál elegir según tu caso de uso.
Guía completaLa amenaza de los deepfakes de voz: guía completa 2025
Todo sobre los deepfakes de voz: cómo funcionan, casos reales de fraude, cómo detectarlos y cómo proteger tu empresa. Guía actualizada 2025.
Caso de estudioCaso de estudio: banco argentino evoluciona de agente humano a voicebot a biometría de voz
Análisis comparativo de tres modelos de autenticación en un banco argentino: agente humano, voicebot con TTS, y biometría de voz. Costos, tiempos y ROI.
¿Querés implementar biometría de voz?
Agendá una demo y descubrí cómo Phonomica puede ayudarte.